TECH 152 A Crash Course in Artificial Intelligence, 1st class
This week I started TECH 152 A Crash Course in Artificial Intelligence, which is 2 hours course for 4 weeks through Stanford Continuing Studies that is taught by Ronjon Nag and Artem A. Trotsyuk.
The course provides a high-level overview of AI techniques. Through pre-built hands-on exercises, discusses on how current AI platforms compare with how the brain works, how systems actually “learn,” and how to build and apply neural networks. It’ll also have discussions on the societal and ethical issues surrounding the real-world applications of neural networks. The course description states that “by the end of the course, students will understand how AI techniques work so they can:
(1) converse with neural network practitioners and companies;
(2) be able to critically evaluate AI news stories and technologies; and
(3) consider what the future of AI can hold and what barriers need to be overcome with current neural network models.”
I brought one of the recommended books, Make Your Own Neural Network by Tariq Rashid, the other being Deep Learning with Python by Francois Chollet.
The tentative weekly outline of the course:
Week 1:
Class structure, Broad overview of AI, machine Learning, Deep Learning
How does a neural network work? Perceptrons, Neural networks with real numbers.
Playing with Tensorflow Playground
Week 2:
Evaluating AI Systems, over and under fitting,
Advanced neural networks: Convolutional Neural Networks, Playing with Google
Collab Neural Networks:
Correlation and Causal Inference
Applications: Speech Recognition, handwriting recognition, AI for climate change
LSTMs, End-To-End Neural Networks, Reinforcement Learning
Generative Adversarial Networks
Week 3:
Careers in AI How to run an AI
How to get advantages in AI development
Natural Language Processing and Understanding: Methods, Applications and Frontiers
Generative AI and ChatGPT
Week 4:
AI in Healthcare
AI for drug discovery
AI in longevity
Boundaries of humanity: intelligence in humans, machines and animals; Societal implications of AI
A classmate, Donna Williams, summarized the first class wonderfully:
“A neural network is a type of computational model inspired by the biological neural networks found in the human brain. It is a fundamental component of machine learning and artificial intelligence. The basic idea behind a neural network is to mimic the way the human brain processes information by connecting artificial neurons in layers to perform complex tasks, such as pattern recognition, classification, regression, and decision-making.
A typical neural network consists of the following components:
1. Input Layer: It receives the raw input data and passes it to the subsequent layers.
2. Hidden Layers: These are one or more layers sandwiched between the input and output layers. Each hidden layer is composed of multiple neurons (also called nodes or units), and they process the information passed from the previous layer.
3. Output Layer: The final layer of the neural network that produces the results or predictions.
Each connection between neurons has an associated weight, which determines the strength of the connection. During the training process, these weights are adjusted to minimize the difference between the predicted output and the actual output, allowing the network to learn from the data and improve its performance over time.
Neural networks are typically used in supervised learning tasks, where the model is trained on labeled data, but they can also be applied in unsupervised and reinforcement learning settings. Deep Learning is a subset of neural networks that involves training models with multiple layers, often called deep neural networks, to handle more complex and abstract features in the data.
ReLu seems to be easier to use to train data, in deep neural networks, we tinkered with a data set creating neurons to solve a ladybug, worm type sort.”
Below are some highlights and notes that I took during the class:
Types of AI
Symbolic Processing - Need an expert
Rules based systems
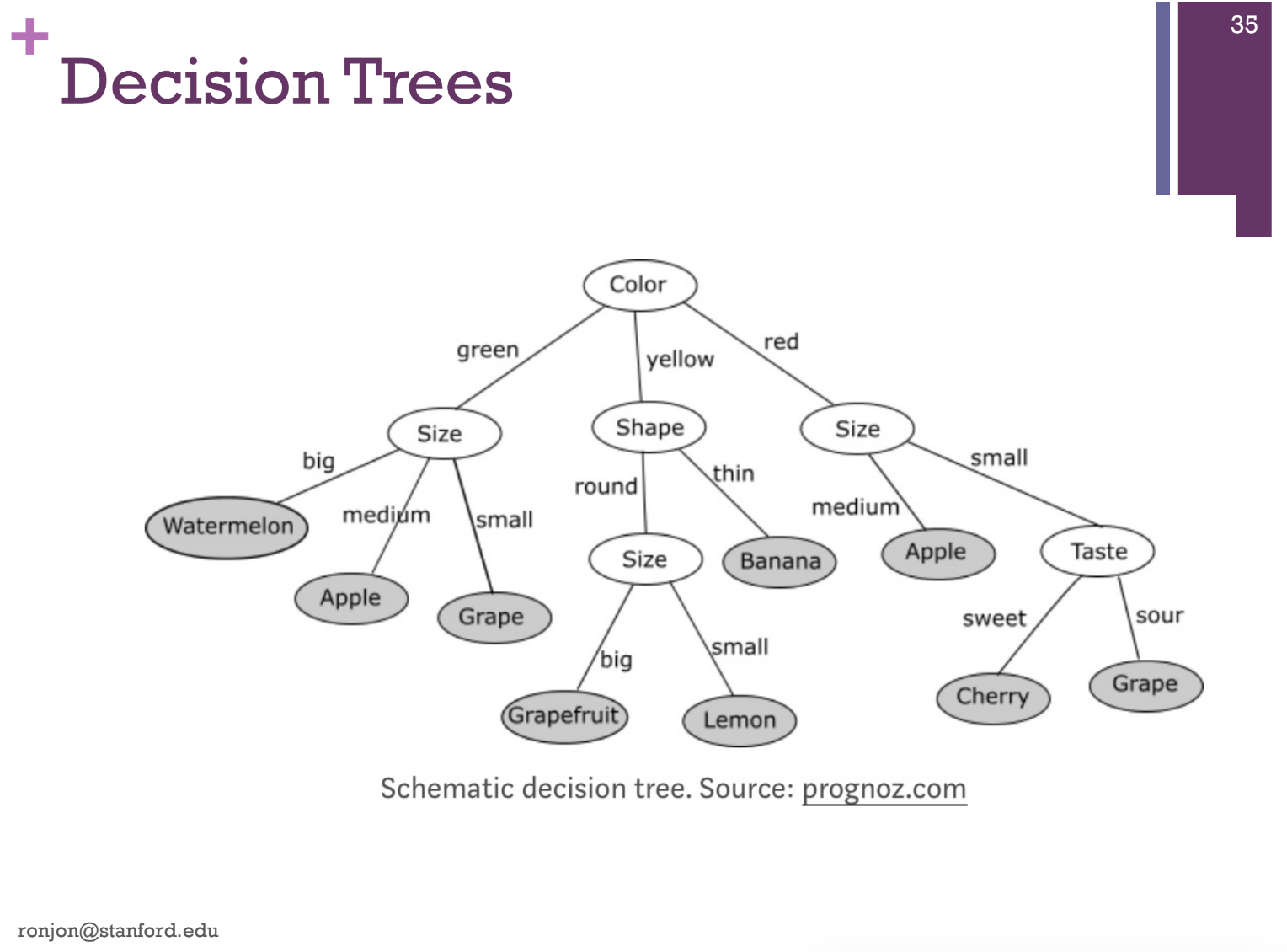
Machine Learning Systems – Needs Data
Bayesian statistics
Hidden Markov models
Neural Networks/Deep Learning
Genetic Algorithms
SVMs – Support Vector Machines
Random Forests
Supervised learning
Learning from Labeled data: “Ground Truth” data
Most systems we see are supervised learning systems
Unsupervised Learning
Unlabelled data
Clustering
Search for patterns
Anomaly detection
Principal Component Analysis
Vector Quantisation
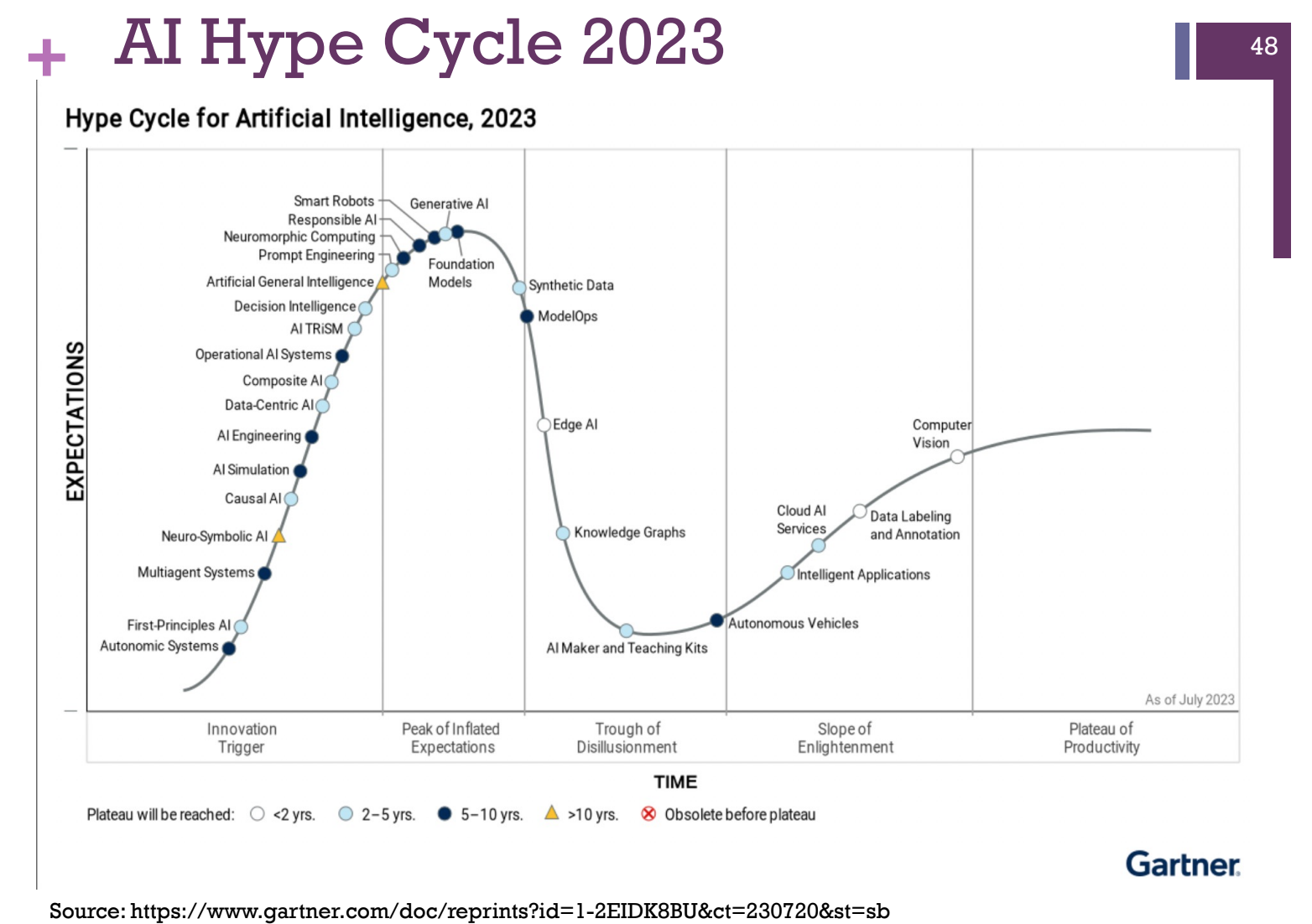
Something super interesting was that Ronjon presented the idea that AI has had several summers and winters and that we are currently in a summer.

He also presented AI Hype Cycle for 2021, 2022 & 2023 and the trends were interesting
Weak AI refers to narrow embodiments of an AI – kind of an AI tool
Strong AI refers to a machine with consciousness, sentience and mind
Artificial general intelligence (AGI) is a machine with the ability to apply intelligence to any problem, rather than just one specific problem.
Neural Networks
Are inspired by brain-like processes
Have training algorithms to compute the parameters
Back propagation: is an algorithm that is designed to test for errors working back from output nodes to input nodes
Types
Feed forward neural networks
Autoencoder
Recurrent Neural Networks
Convolutional Neural Networks
Adversarial Neural Networks
Deep Learning
Radial Basis Functions
Deep Learning
Deep Learning
Technically neural networks with many layers
Usually refers to more advanced embodiments of neural networks
Convolutional neural networks
Reinforcement Learning
Below is a simplified version
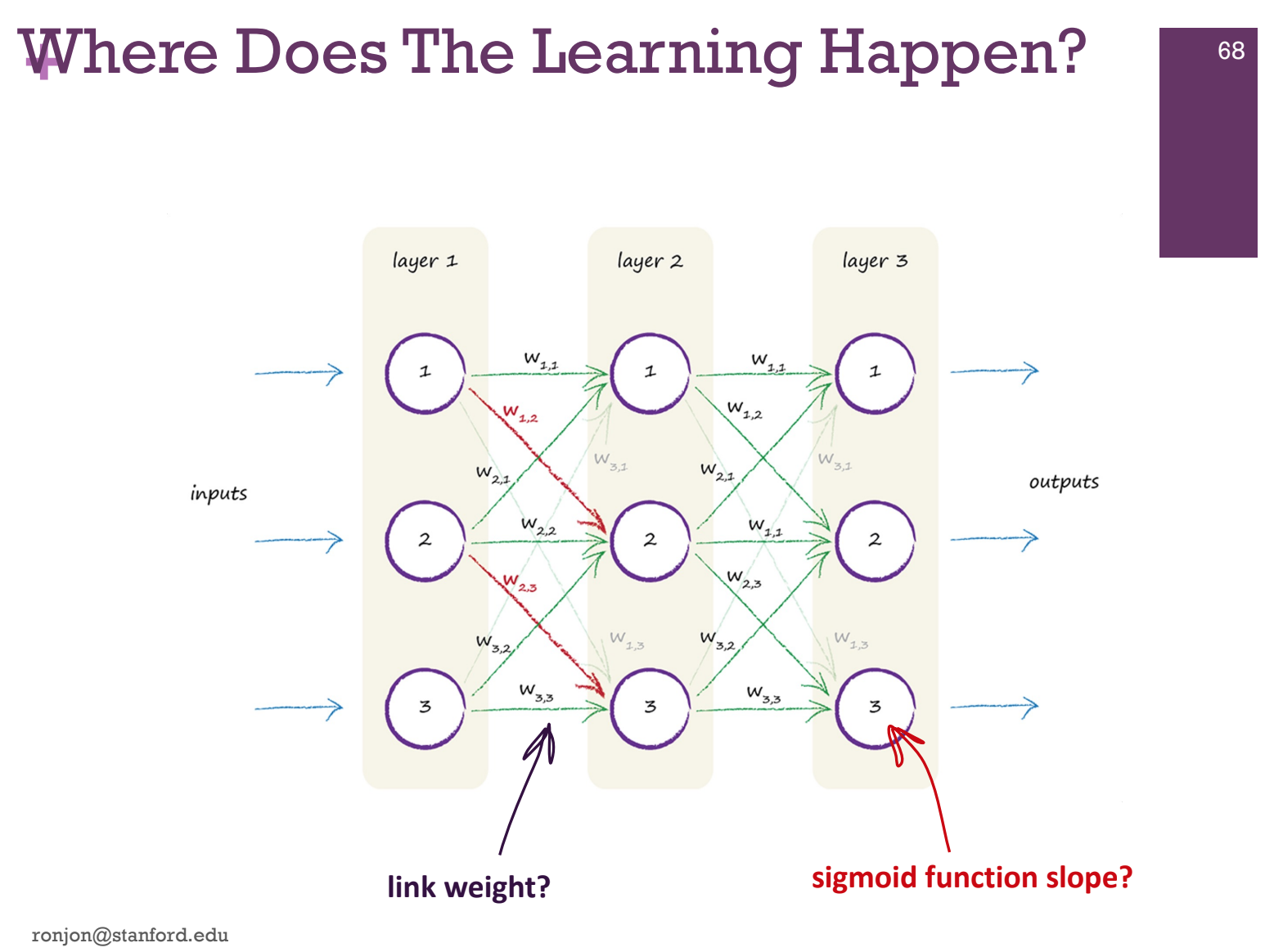
Middle layers are called “hidden layers”
“ITERATIVE LEARNING” to get closer and closer to the answer
If there is an error, adjust the parameters
Adjust the parameters in proportion to the error – learning rate
Iteration and recompute
The architecture
How are the neurons arranged
Number of layers
Number of neurons in each layer
Various application specific architectures
Convolution neural nets
Recurrent neural nets
The weights
What are the weight values
Which weights are pruned away
How to find:
Brute force – try every combination of weights till we get the right answer
Too intensive
Use gradient descent
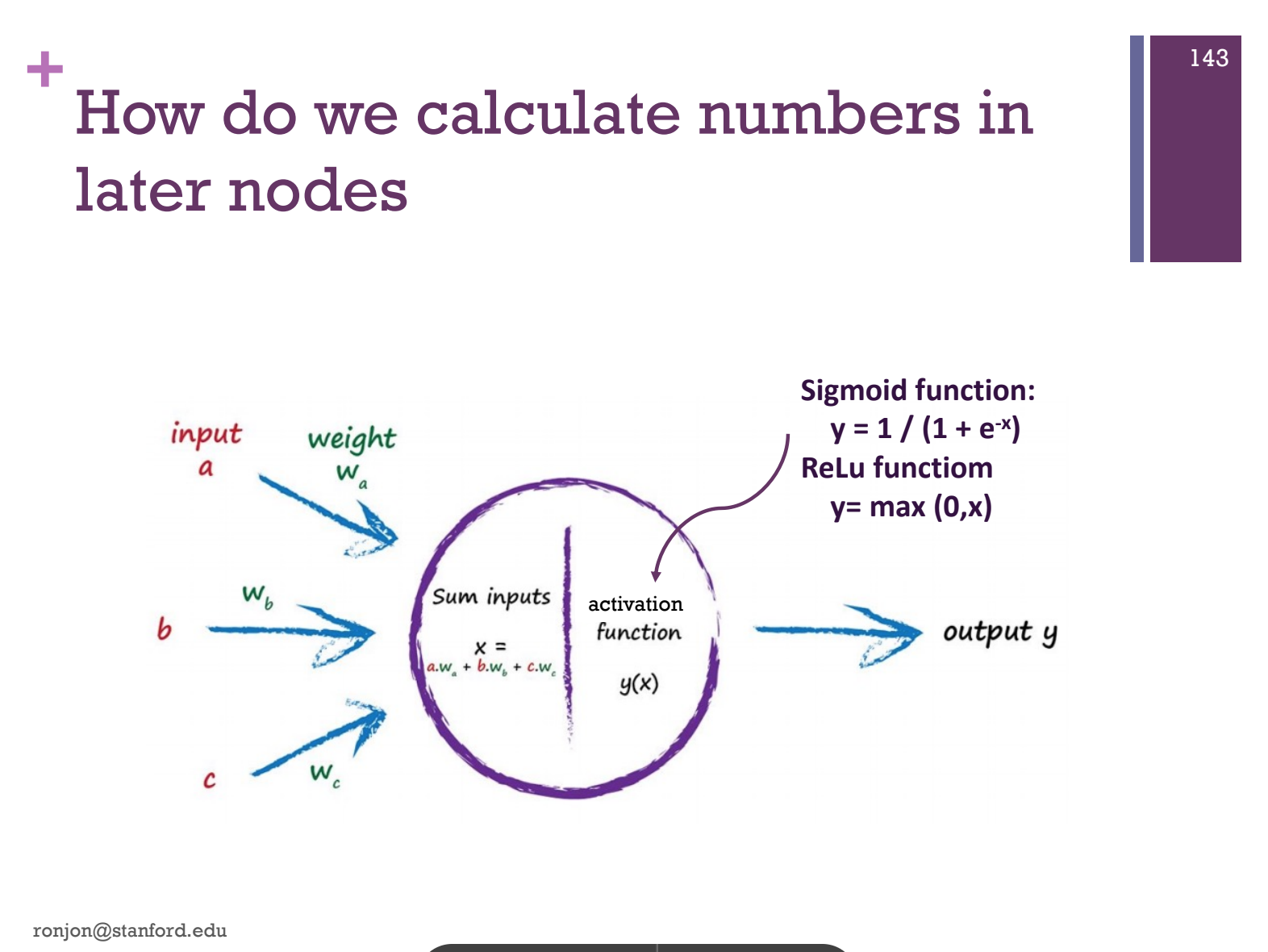
The activation function
Rectified Linear Units (ReLu)
Sigmoid function
Each node is a function, taking in several inputs, processing them and providing an output
The main characteristics of deep learning are:
The architecture
The weights
The training algorithm
Slow to train
Faster for classification
No iteration required
Works much faster on GPUs or specialized hardware
For training – specialized hardware helps a lot
For classification may not be needed depending on the problem
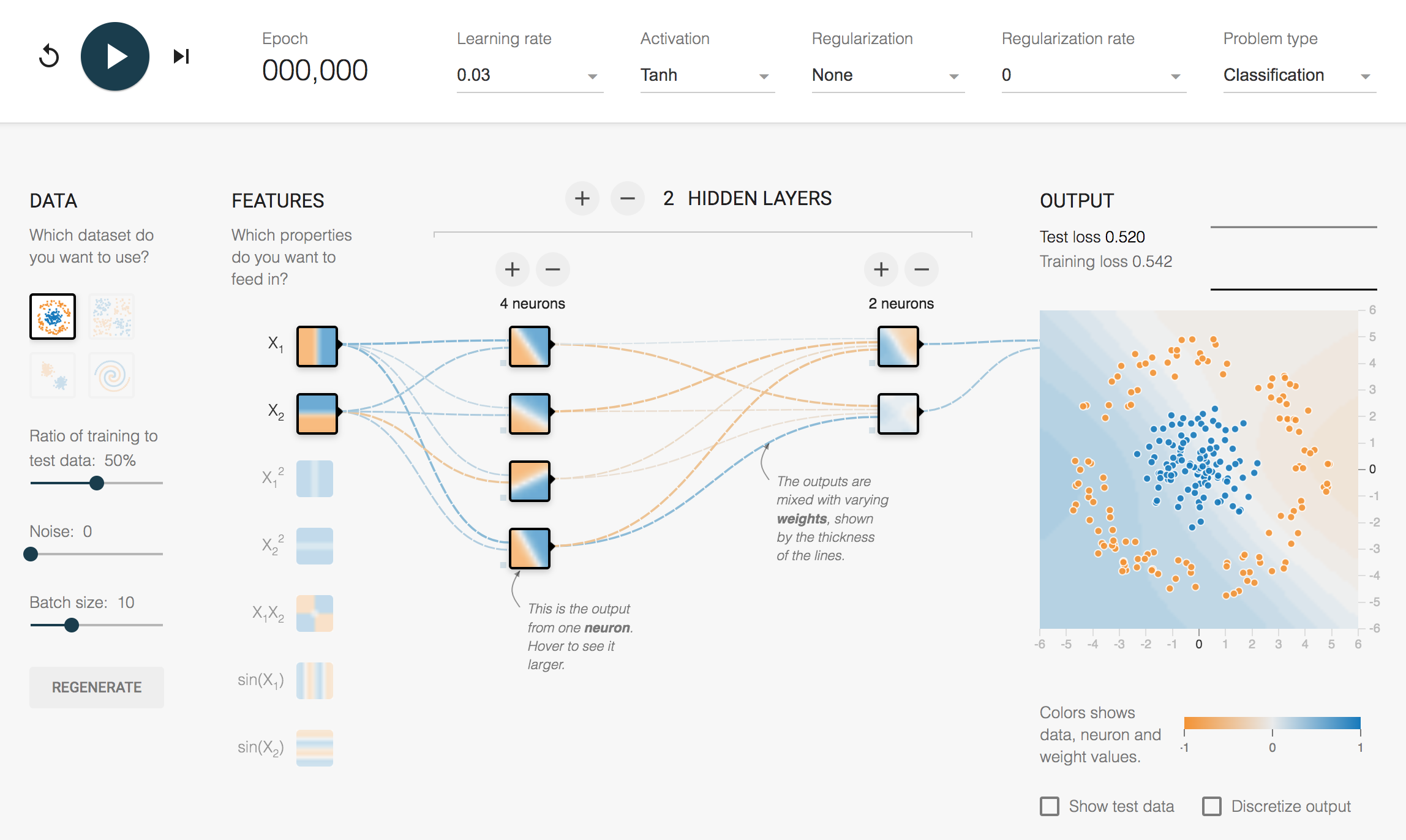
The last 15 or so minutes were spent on playing with Tensorflow Playground.