TECH 152 A Crash Course in Artificial Intelligence, 2nd class
Week 2 class was about Neural Network: a method in artificial intelligence that teaches computers to process data in a way that is inspired by the human brain.
A light review from last week
Running a Neural Network Code
Evaluating AI Systems, over and under fitting,
Convolutional Neural Networks
Generative Adversarial Networks
Natural Language Processing and Understanding
1. A light review from last week
When it comes to choosing parameters it’s best to start with a model for a similar problem and to simplify the architecture (like converting data to numbers. After that, to start with one layer and go deeper if needed. It’s surprising how much of figuring out which parameters and how many layers is basically trial and error – like twisting knobs of a old radio to find a radio station and then fine tuning once you find a sign.
2. Running a Neural Network Code
We were able to play with the MNIST database (Modified National Institute of Standards and Technology database), which is a large database of handwritten digits: MNIST Dense Neural Network code.
3. Evaluating AI Systems, over and under fitting
High precision means that when you do say that someone is honest, you're usually right about it. This is about how many politicians in your list are actually honest, out of all the ones that you've added to the list.
Precision is the ratio of true positives to all positives
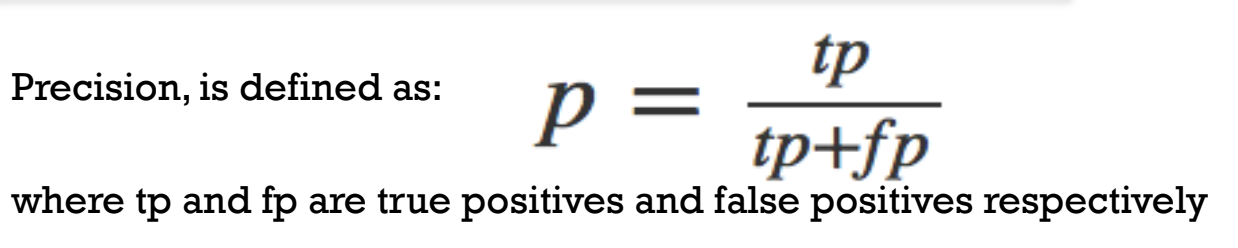
High recall means that you can identify most of the honest politicians out there. This is about how many honest politicians you've added to your list, out of all the ones that exist.
Recall is the ratio of true positives to all that were classified correctly

F1 score takes account of false positives and false negatives (but assumes both have equal cost)
F1 Score : 2 x (precision x recall)/(precision+recall)
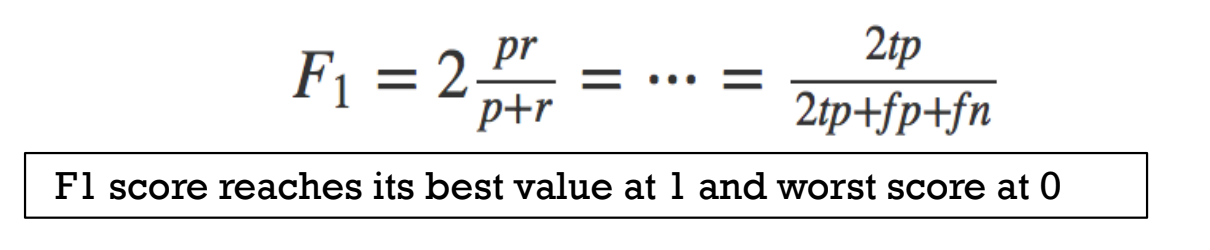
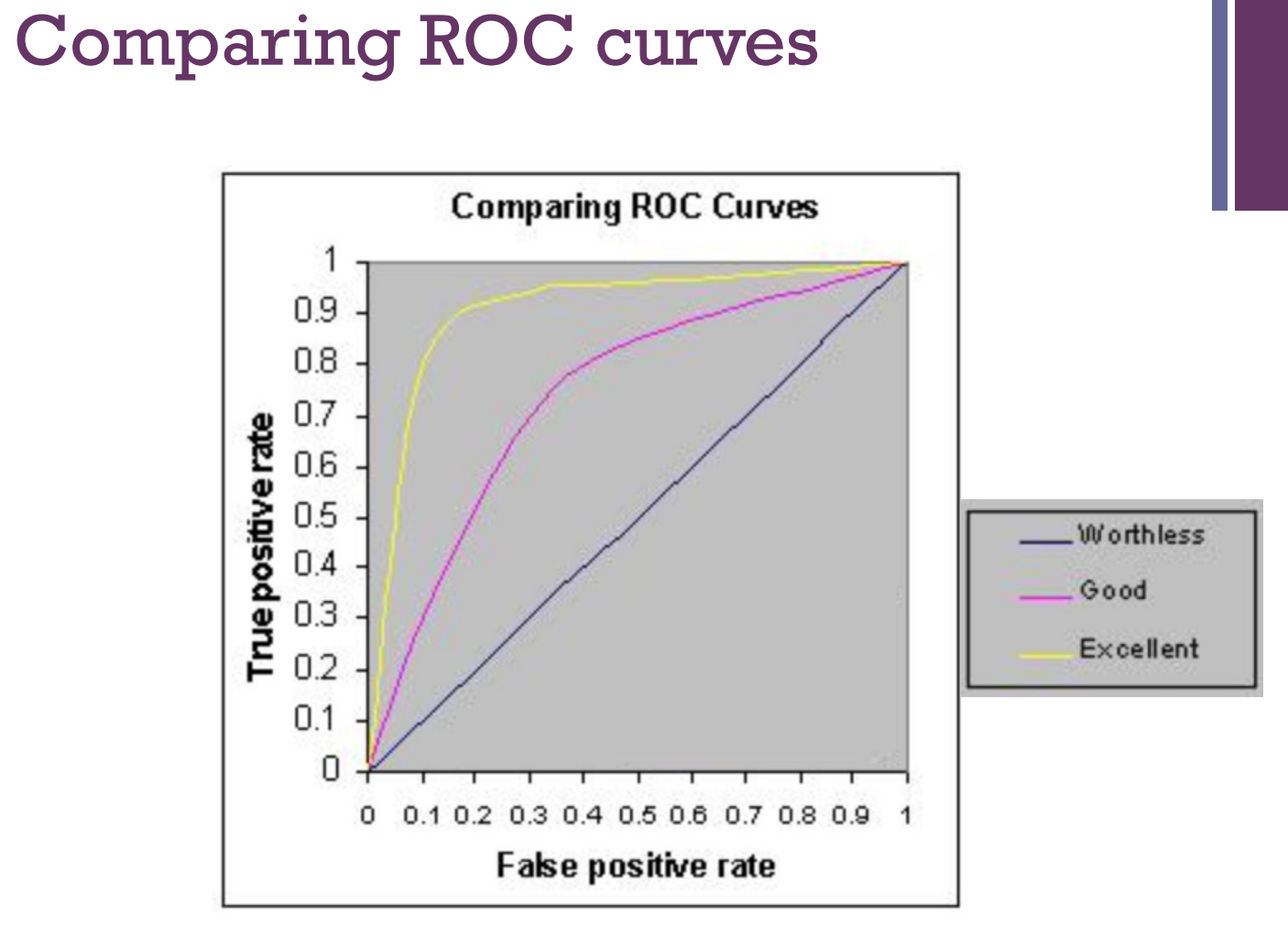
Receiver Operating Characteristic (ROC) Curve: Plot true positive and true negative rates
ROC Area under curve (AUC):
– 1.0: perfect prediction
– 0.9: excellent prediction – 0.8: good prediction
– 0.7: mediocre prediction – 0.6: poor prediction
– 0.5: random prediction – <0.5: something wrong
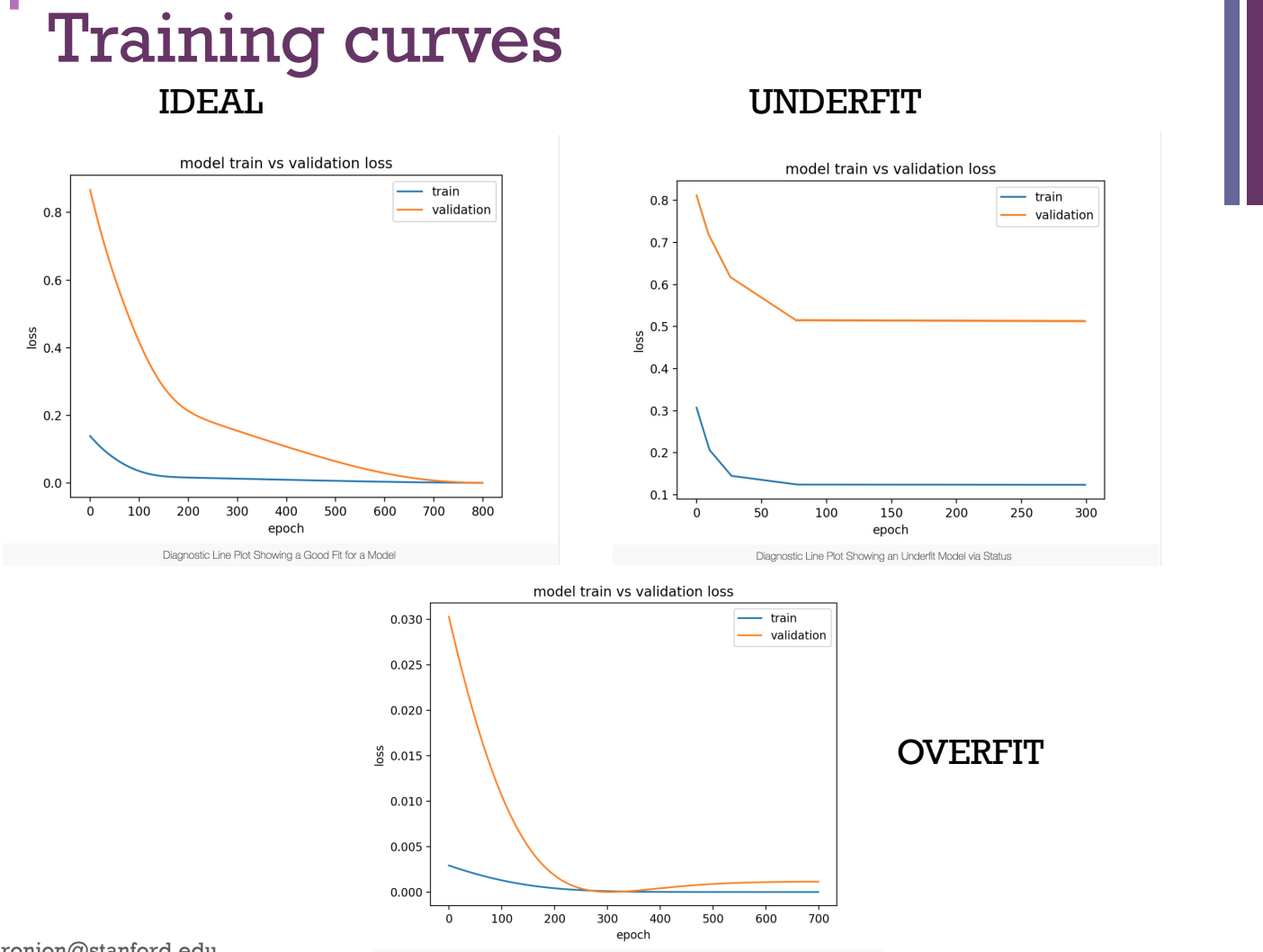
Overfitting: Occurs when a function is too closely fit to a limited set of data – ie. Fits the data ”too well”
When model is overly complex – eg. Too many hidden layers or neurons.
When a new test data point (not in the training data), the model fails to classify the new point
High variance and low bias
Underfitting: Occurs when the model cannot capture the underlying trend of the data.
Specifically, underfitting occurs if the model or algorithm shows low variance (all data points close to the mean) but high bias. Underfitting is often a result of an excessively simple model
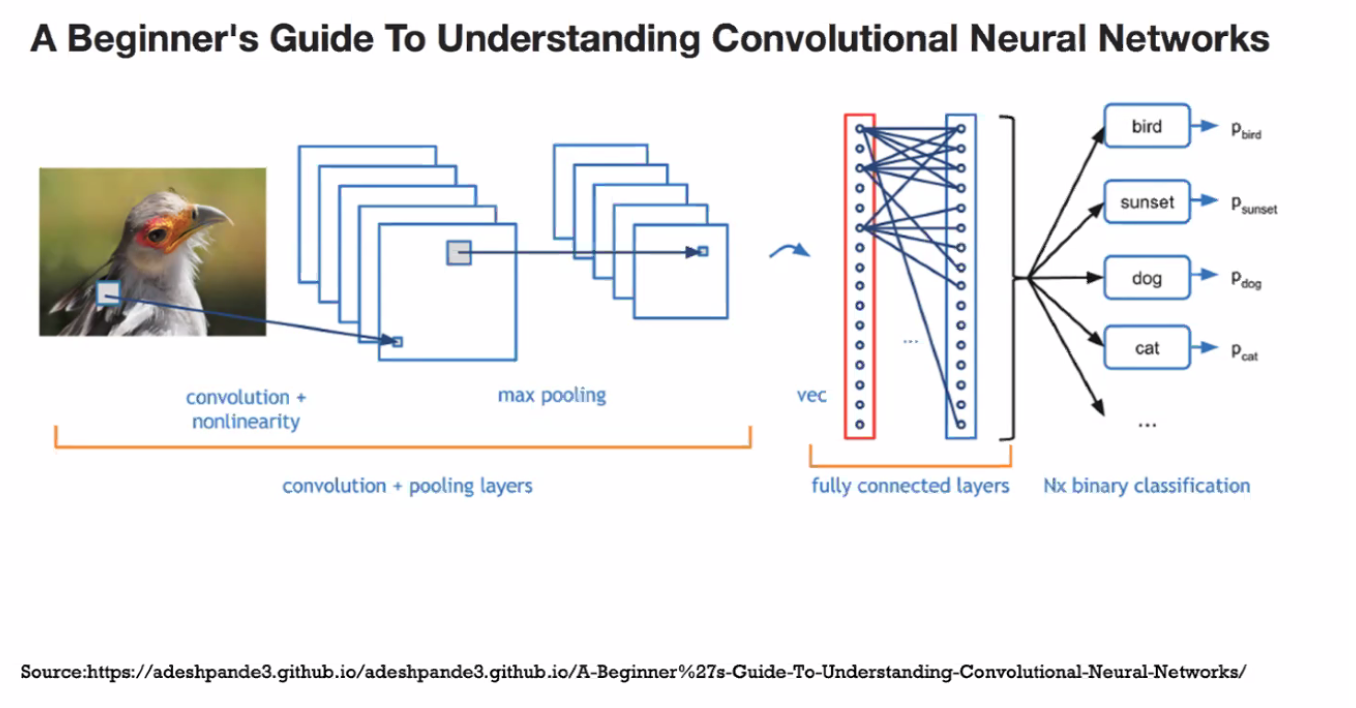
4. Convolutional Neural Networks (ConvNets)
Convolutional Neural Networks (ConvNets): is a Deep Learning algorithm that can take in an input image, assign importance (learnable weights and biases) to various aspects/objects in the image, and be able to differentiate one from the other.
Converts images into numbers, then applying a filter to create Convolved Feature
Slow to train
Fast(er) for classification
No iteration required
‘filter‘ or ‘kernel’ or ‘feature detector’ and the matrix formed by sliding the filter over the image and computing the dot product is called the ‘Convolved Feature’ or ‘Activation Map’ or the ‘Feature Map‘. It is important to note that filters acts as feature detectors from the original input image.
Spatial Pooling (also called subsampling or downsampling) reduces the dimensionality of each feature map but retains the most important information. Spatial Pooling can be of different types: Max, Average, Sum etc.
Downsample input samples – form of data pre-processing
Reduces dimensionality
Helps over-fitting
Reduces computational cost

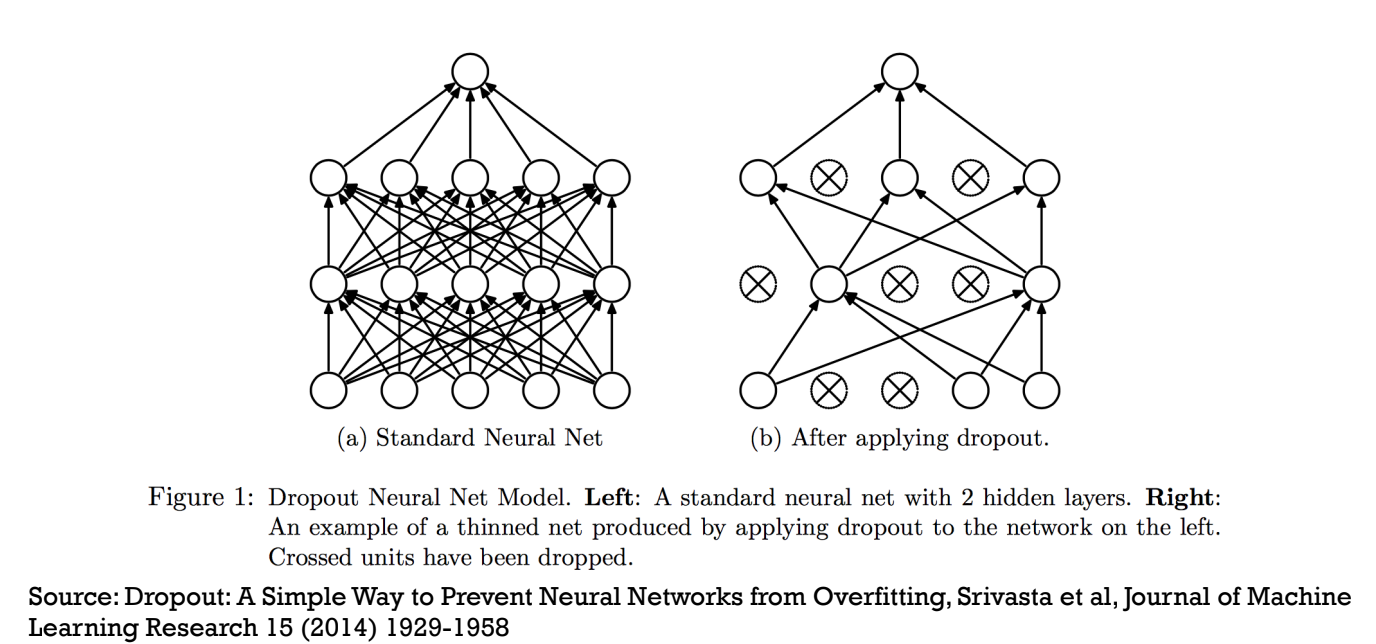
Dropout: refers to dropping out the nodes (input and hidden layer) in a neural network. All the forward and backwards connections with a dropped node are temporarily removed, thus creating a new network architecture out of the parent network. The nodes are dropped by a dropout probability of p.
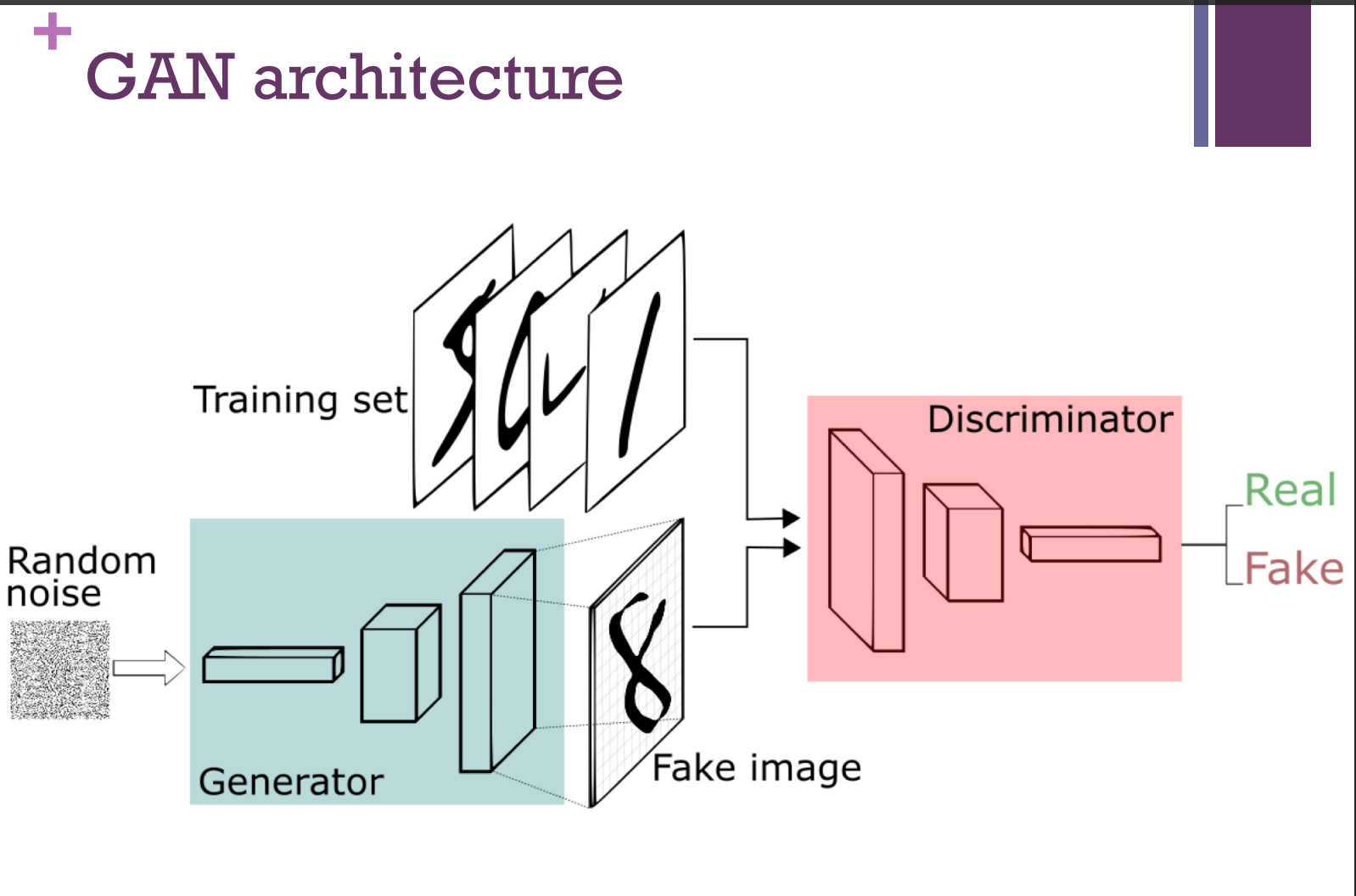
5. Generative Adversarial Networks
Generative Adversarial Networks GAN: are an approach to generative modeling using deep learning methods, such as convolutional neural networks.
One network produces answers (generative)
Another network distinguishes between the real and the generated answers (adversarial)
Train these networks competitively, so that after some time, neither network can make further progress against the other.
GANs are hard to train and can get into mode collapse
How to train GANs
Step 1: Define the problem. Do you want to generate fake images or fake text. collect data for it.
Step 2: Define architecture of GAN. Define how your GAN should look like.
Eg. multi layer perceptrons, or convolutional neural networks? Depends on problem – eg. Images or numbers
Step 3: Train Discriminator on real data for n epochs.
Step 4: Generate fake inputs for generator and train discriminator on fake data. Get generated data and let the discriminator correctly predict them as fake.
Step 5: Train generator with the output of discriminator. Now when the discriminator is trained, you can get its predictions and use it as an objective for training the generator. Train the generator to fool the discriminator.
Step 6: Repeat step 3 to step 5 for a few epochs.
Implications
Potentially you can duplicate almost anything
Generate fake news
Create books and novels with unimaginable stories
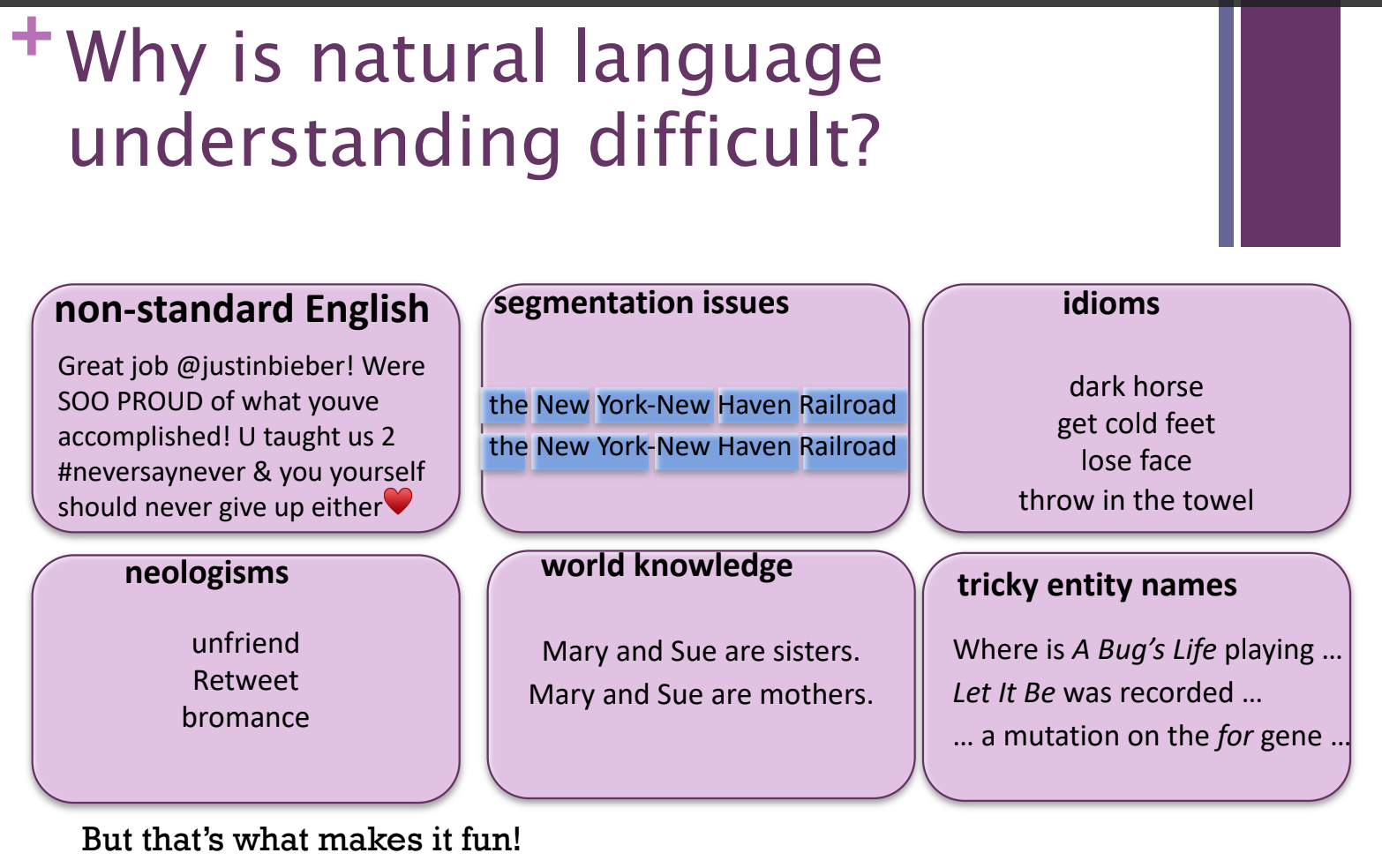
6. Natural Language Processing and Understanding
Processing: Manipulation of text and other media related to language
Text, handwriting, speech
Language Statistics
Read, decipher, understand, and make sense of the human languages in a manner that is valuable
Understanding
Mapping words to knowledge
Acting on text corpora
Used in language processing
Speech recognition
Handwriting Recognition
Language Translation
Forensics: writer recognition
Speech and language technology relies on formal models, or representations, of knowledge of language at different levels
phonology and phonetics
morphology, syntax, semantics
pragmatics and discourse.
Methodologies and technologies
NLP Pipeline
Statistical/ML Tools
Knowledge Graphs
Language Models
Deep Networks
Applications
Document Processing
Question Answering
Machine Translation
Conversational Assistants
Language processing
Part-of-speech tagging: It involves identifying the part of speech for every word.
Noun, verb, etc.
Parsing: It involves undertaking grammatical analysis for the provided sentence.
Sentence breaking: It involves placing sentence boundaries on a large piece of text.
Stemming: It involves cutting the inflected words to their root form
Tradition and traditional have the same stem “tradit”
Semantics
Named entity recognition (NER): It involves determining the parts of a text that can be identified and categorized into preset groups.
names of people
names of places.
Word sense disambiguation: It involves giving meaning to a word based on the context.
Apple the fruit vs Apple the computer
Natural language generation: It involves using databases to derive semantic intentions and convert them into human language.